What is SFASTA?
Genomic and bioinformatic-adjacent sequences (RNA, Protein, Peptides) are stored as FASTA files. Sequencing reads off a machine are stored as FASTQ files, adding a quality score associated with each nucleotide. Currently, these are non-human-readable plaintext files. As sequencing increases, we need to be able to process many more gigabytes and terabytes of files rapidly and with random access (currently solved by bgzip/tabix). becomes incredibly important.
SFASTA, my focus-on-random-access-speed FASTA/Q format replacement, has worked well for medium and large FASTA files, defining large as anything smaller than NT nucleotide database (~203Gb gzip-9 compressed, but likely larger whenever you are reading this). Small files did not benefit from stream compression and crazy indices, although the time cost for small files is irrelevant. But the conversion of nt to SFASTA took an inordinate amount of time, and reading the index into memory did as well. While still smaller and faster than gzip-9, this does not accomplish what I want.
Why?
FASTA files are frequently compressed with an outdated, slow, inefficient compression algorithm (gzip). Modern alternatives provide better compression ratios, decompression ratios, and faster throughput. The speed of reading FASTA files is quite important, with multiple tools that try to be the fastest. Clearly, this is an unsolved problem, and sticking to a text-based, non-human-readable format is a choice that only occurs due to the momentum of existing tools.
Genomics is moving to “Genomics at scale” and away from single-genome analyses. A flat file format adds unnecessary processing time to query hundreds of genomes instantly. For my own usage, I’d like to be able to query NT and fill up the GPU with random, on-the-fly examples. This is entirely achievable with modern computers but not with outdated file formats and compression.
What does SFASTA mean?
SFASTA previously stood “Snappy FASTA” as it used the Snappy algorithm, but now it uses ZSTD. The name remains as the command remains sfa, which can be typed with one hand on the home line on a standard keyboard.
Further Speed-ups
So, it’s clear my custom-built index was a failure. Enter B+-tree. While fighting post-COVID brain fog, I eventually managed to build a naive implementation. My benchmarks for creating a tree with 128 million key/value pairs threatened to take over 20 hours (for 20 samples, so 1 hour each). Hacking away at that, I did shrink it, but only some. Then, I modified a copy to use the sorted-vec crate. Finally, while reading further up on the topic, I discovered fractal trees, which merely add a buffer to each node and process it when calling for a flush or exceeding the buffer size. I am now within a minute of creating such a large index. For this implementation, the fractal tree uses sorted-vecs as the key vector.
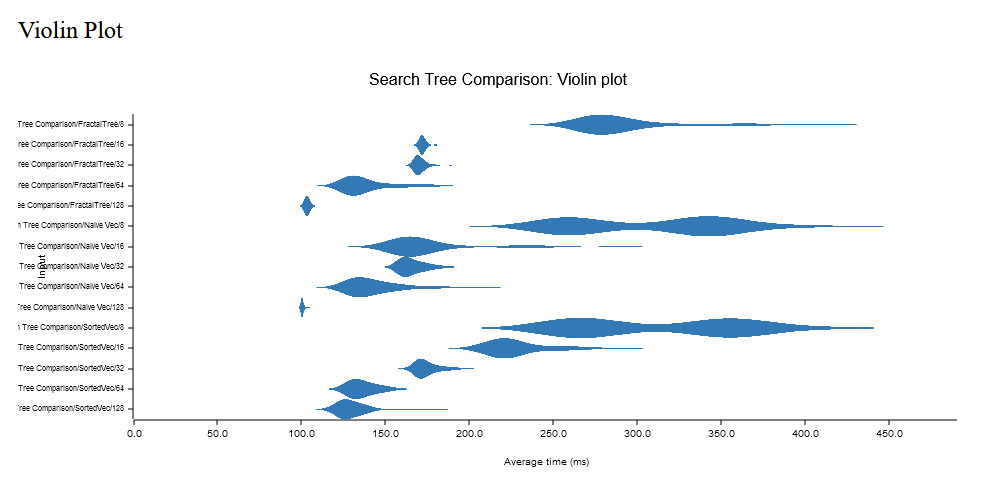
For B+ trees and fractal trees, the order of the nodes (how many children each node can have) is incredibly important. For creating trees, an order of 32 seems to be the sweet spot (this is tested on u64 as both keys and values). For fractal trees, 64 with a larger buffer seems to be the sweet spot. The figure below shows the fastest order, 64, and buffer 128. The image below is for 1 million items.
Text is difficult to read, but the number is the order, and for fractal trees, the second number is the buffer size.
The Big Tree
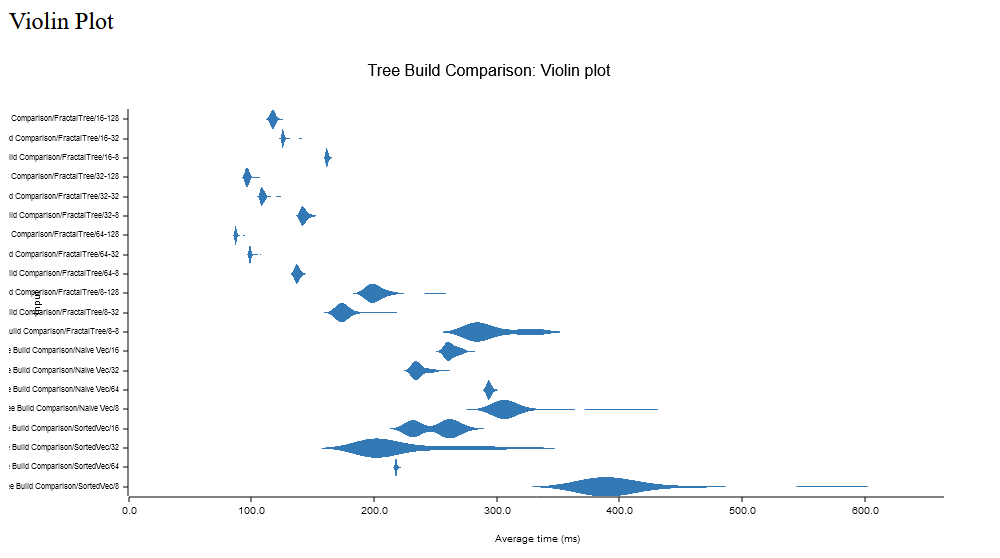
My NT test dataset is a bit over 128 million entries, u64 range 0 to 128_369_206, with keys and values as the xxh3 hashed integer. You can see the spread below. Here the larger buffer size (up to 256) performs the best, but many are in the less than a minute sweet spot.
Searching the Tree
Now that building a tree for NT takes under a minute, compressing and queueing the nucleotide sequences and IDs into the file will be the bottleneck for creation. Building the tree is also a one-time cost, so it is not the highest priority. The focus now is searching the tree, which will happen quite frequently depending on the final use case.
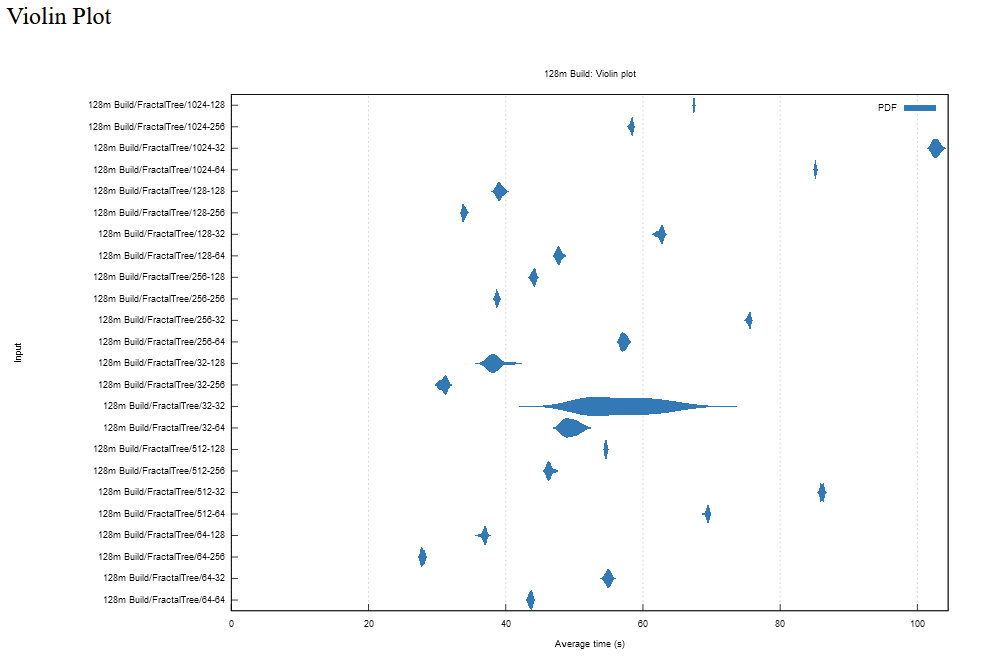
I’m just now getting to start on this, but as you can see below, where input is the order of the nodes, a larger order decreases the time to find a key. This is an even better sign for the fractal trees, as they are more efficient with larger orders. The image below shows very little difference, with sorted vec having a bit of a slowdown. I have no idea why, possibly due to a line of code that did not change as I’m simultaneously playing around with three versions. As my fractal tree implementation uses sorted-vec, these results are quite equivalent. The search code is nearly identical. This is the next step.
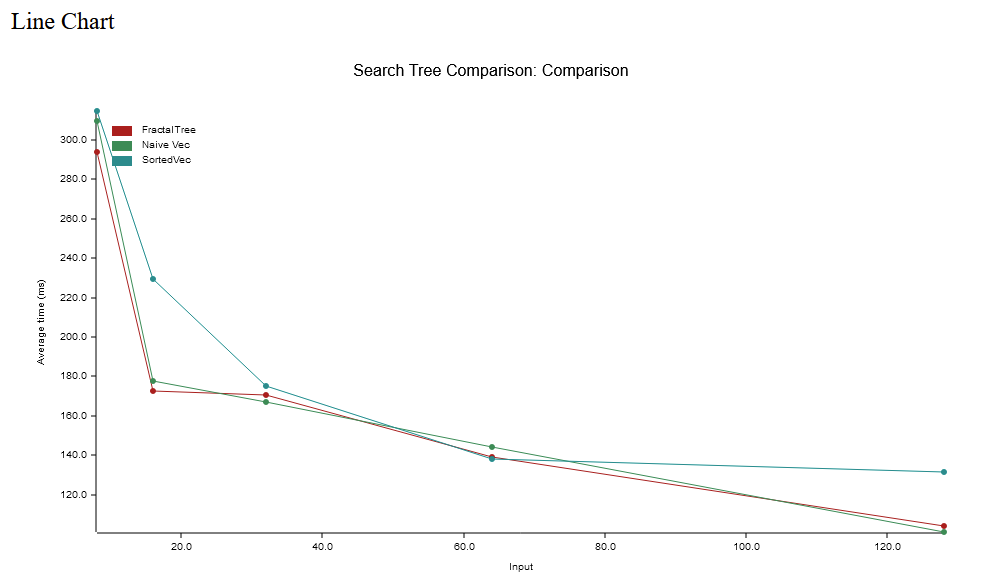
Here, the x-axis is node order, with tests for 16, 32, 64, and 128.
What Hasn’t Worked
- 2bit/4bit nucleotide encodings – did not increase throughput or decrease on-disk size. Still worth further investigation.
Immediate Next Steps
As this is a write-once file format, at least at this stage, I plan to do the following:
- Smaller struct for read-only mode, i.e., buffer is no longer needed
- Benchmark sorted-vec against Eytzinger order
- Load only parts of the tree from disk, have efficient serialization
- Possibly try a bumpalo arena for querying the on-disk tree
- Batch insertion – Maybe this was all for naught
- Stream VBytes storage for keys/values of tree?
Ultimate Goals
- LD_PRELOAD to work with existing tools
- Python library
- C API
I’ve been programming in Rust for a couple of years and have experimented with many different things, including the bevy game engine. I would still argue I’m a middling skilled Rust developer, as I’m also a population geneticist. Thus, some weeks are spent without writing a single line of code or only writing in Python for statistical analysis. Thus, I expect much room for improvement, although I’m proud of where I’ve gotten this so far.
Plots made with criterion.